A Brief Introduction to Recommender Systems
If you’ve ever had a social media account (Facebook, Twitter), purchased something online (Amazon), or consumed content from a streaming platform (Spotify, Netflix), there’s a good chance that you’ve been influenced by a recommender system. Recommender systems help drive user engagement on these platforms by generating personalized recommendations based on a user’s past behaviour. Some recommendations that we may encounter in real-life include:
- “Customers who bought this item also bought…” (Amazon)
- “Because you watched this show…” (Netflix)
- Made for You: Discover Weekly playlist (Spotify)
- “Based on your reading history…” (News article platform)
- “You and Bob are 99% compatible” (OkCupid)

Amazon: "Customers who bought this item also bought..."
Behind the scenes, a recommender system is simply a machine learning algorithm that predicts future behaviour based on a user’s historical preferences. It looks at demographic data, behavioural data, and item attributes to predict which items a user will find most relevant.
In this post, we will cover the motivation behind recommender systems, the difference between implicit and explicit feedback, collaborative filtering and content-based filtering, and techniques used to evaluate recommender systems.
Motivation Behind Recommender Systems
In order to understand the motivation behind recommender systems, we need to look back at the history of e-commerce.
Before the rise of e-commerce, things were sold exclusively in brick-and-mortar stores. A store’s inventory was limited to the physical space of the store and products that didn’t sell well were unprofitable. With a fixed inventory, merchants were motivated to sell only the most popular mainstream products.
In the mid 1990s, the introduction of the online marketplace revolutionized the retail industry. This new type of digital marketplace allowed for unlimited inventory, which meant that merchants could expand their product offerings to less mainstream, more niche items. As Chris Anderson describes in The Long Tail, “the mass market is turning into a mass of niches”. By overcoming the limitations of inventory, niche products are able to outsell the bestsellers. As a result, e-commerce businesses are seeing more value in niche products than before.
That being said, having a massive selection of offerings doesn’t necessarily mean that users will buy more stuff. In 2000, two psychologists from Columbia and Stanford University conducted a study at a supermarket tasting booth (see paper here). One booth had 6 samples of jam; the other had 24.

The Tasting Booth Experiment (Iyengar and Lepper, 2000)
While the booth with more samples attracted more customers, the booth with fewer samples had a higher conversion rate. In fact, people who stopped at the booth with fewer samples were 10 times more likely to follow through with a jam purchase as compared to people who sampled from the booth with more options. This observation is known as “choice overload”: if a person is presented with too many options, they are less likely to buy. Choice overload extends beyond grocery shopping and can affect the decisions people make in online retail too. Recommender systems alleviate choice overload by reducing the search space and identifying the most relevant, high-quality items for users.
Explicit vs. Implicit Feedback
Recommender systems are fuelled by user feedback. As we collect information on what a user likes and dislikes, we are able to build a more accurate user profile and generate more relevant recommendations tailored to the tastes of that user.
User feedback comes in two forms: 1) explicit feedback, and 2) implicit feedback. Explicit feedback is when a user directly likes or rates an item. Examples of explicit feedback include rating a movie on a 1-5 Likert scale, “liking” a friend’s Facebook post, or writing a positive review for a restaurant. Implicit feedback is more subtle and attempts to infer a user’s preferences based on their indirect behaviour. Examples of implicit feedback include a user’s purchase history, how many times they replayed a song, how quickly they binge-watched a series, or how long they read an article for.
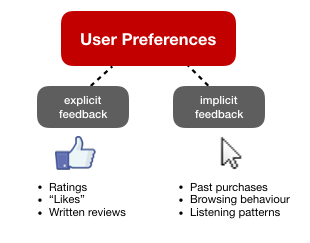
Explicit vs. Implicit Feedback
By feeding user preferences into a recommender system, we get predictions about a user’s future behaviour. Which songs will they like next? Which movies will they binge watch? Which products will they buy next? These predictions are called recommendations.
Collaborative and Content-Based Filtering
The two most common recommender system techniques are: 1) collaborative filtering, and 2) content-based filtering.
Collaborative filtering is based on the concept of “homophily” - similar people like similar things. The goal is to predict a user’s preferences based on the feedback of similar users.
Collaborative filtering uses a user-item matrix (also known as a “utility” matrix) to generate recommendations. This matrix is populated with values that indicate a user’s degree of preference towards a given item. These values can represent explicit feedback, implicit feedback, or a hybrid of both. It’s very unlikely that a user has interacted with every item, so in most cases, the user-item matrix is very sparse.

User-item Matrix
In the user-item matrix above, we see that Anne and Jim have very similar tastes in movies. For example, they both like Titanic and A Star Is Born but dislike Harry Potter and Shawshank Redemption. Anne hasn’t watched King Kong yet but Jim has and he rated it highly. Since Anne and Jim have similar rating patterns, we can assume that Anne will also rate King Kong highly and thus, we should recommend this movie to her. This process of comparing rating patterns among users is called collaborative filtering.
Given sufficient data, collaborative filtering performs extremely well. However, in cases where we have a lot of new users and new items, we run into an issue called the cold-start problem. Collaborative filtering won’t work on users and items that don’t have any interaction data. To overcome this problem, we can use a technique called content-based filtering.
Content-based filtering handles the cold-start problem because it doesn’t need any interaction data to generate recommendations. Instead, it looks at user features (e.g., age, gender, spoken language, employment, etc.) and item features (e.g., movie genre, release date, cast).

User and Item Features
Let’s say a new movie is out and doesn’t have any ratings yet. We can look at its features such as genre and cast to find similar movies with those features. To measure similarity, we first need to represent movies in a n-dimensional space where n represents number of movie features. We can then measure the distance between movies in this n-dimensional space using similarity metrics such as Euclidean distance, cosine similarity, Pearson correlation, and Jaccard distance. The smaller the distance between two movies, the more similar they are to one another.
Suggesting similar movies is called an item-item recommendation. Examples of this type of recommendation include “Because you watched this movie…”, “More Like This”, “Customers who bought this also bought these”, etc. With content-based filtering, which leverages movie features, new movies can still show up in their recommendations despite not having any rating data.
Evaluating Recommendations
The best approach to evaluating a recommender system is to test it in the wild using a strategy called A/B testing. With A/B testing, users are randomly split into two groups. For example, one group of users are served by Recommender System A and another group by Recommender System B. The group that exhibits more user engagement is assumed to have higher quality recommendations. So if users in group A watch more movies and give higher ratings than those in group B, we can conclude that Recommender System A is more effective than Recommender B. Testing recommendations in a live production setting is called “online” evaluation.
In cases where we want to evaluate a recommender system that is still under development, we resort to offline evaluation where recommender systems are tested in a sandbox environment unexposed to users. To evaluate a recommender model offline, we hold out a proportion of user-item interaction data in our user-item matrix. This user-item matrix, which has masked values, is fed into our recommender system to generate predictions for each user-item pair. Let’s say we’re dealing with a user-item matrix that is populated with movie ratings. We can compare the predicted ratings generated from the recommender system against the actual ratings that were held out during training. There are several evaluation metrics that we can use to quantify recommendation performance such as precision@k, recall@k, and root mean squared error (RMSE). With precision@k, we look at the proportion of top-K recommendations that are relevant to the user. It can be described with the following equation:
\[\text{precision@k} = \frac{n_{relevant}}{k}\]where \(n_{relevant}\) represents the number of recommended items that are relevant to the user and \(k\) represents the total number of recommendations. Here, a “relevant” item is one that a user has shown a high degree of preference towards, either through explicit feedback (5-star rating) or implicit feedback (binge-watching the show).
Recall@k is slightly different than precision@k. It looks at the proportion of relevant items found in the top-K recommendations. It can be defined as such:
\[\text{recall@k} = \frac{n_{relevant}}{N_{relevant}}\]where \(N_{relevant}\) represents the total number of relevant items for a given user. Recall aims to minimize the number of false negatives (number of relevant recommendations that didn’t make it to the top-K recommendations), while precision aims to minimize the number of false positives (number of recommendations that were incorrectly identified as relevant). In general, a good recommender system is expected to have a high precision@k and recall@k.
RMSE is another offline evaluation metric that looks at the difference between ratings predicted by the recommender system and ratings given by the users. It can be described with the following equation:
\[\text{RMSE} = \sqrt{\frac{\Sigma{(r_{predicted}-r_{true})^2}}{N_{ratings}}}\]where \(r_{predicted}\) represents the predicted rating generated from the recommender system, \(r_{true}\) represents the actual rating provided by the user, and \(N_{ratings}\) represents the total number of ratings. A low RMSE indicates that the recommender system is able to accurately predict a user’s ratings.
Recent efforts in the field of recommender evaluation have shifted towards new concepts such as novelty, serendipity, and diversity. Research has shown that users are more engaged in recommendations that include novel items, that are serendipitous (i.e., “accidental discovery”), and have a diverse selection. These are also important factors to take into consideration when building a recommender system.
This post has also been published on Medium. It’s a general introduction to recommender systems. For more information on recommenders, check out my tutorial series which walks through how to implement a recommender system of your own using Python.